总的来说,Python的垃圾回收机制是以引用计数为主,同时为了解决循环引用的问题以及提升效率,采取标记-清除和分代收集为辅助办法。
1. 引用计数
引用计数的核心思想是:每一个对象都有一个计数器ob_refcnt用来标记这个对象被引用的次数(比如被1个变量引用则为1,被2个变量引用则为2)。当引用次数为0时,系统会马上回收这个对象。
优点:
-
简单
-
实时性
缺点:
-
维护引用计数消耗资源
-
循环引用
详细介绍:
1.1 引用计数原理
首先介绍Python的对象是如何获取内存空间的。
下面举一个简单的例子
Class Node(object): def __init__(self,val): self.value = valn1 = Node("ABC") 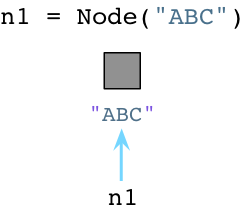
当创建对象时Python立即向操作系统请求内存。(Python实际上实现了一套自己的内存分配系统,在操作系统堆之上提供了一个抽象层。为了简单,不展开说了)
假设我们已经创建了三个Python Node对象:
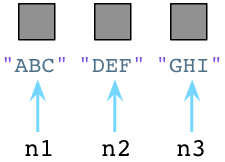
在内部,创建一个对象时,Python总是在对象的C结构体里保存一个整数,称为 引用数。当对象刚被创建时,Python将这个值设置为1:
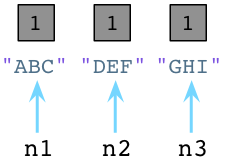
值为1说明分别有个一个指针指向或是引用这三个对象。假如我们现在创建一个新的Node实例,JKL:
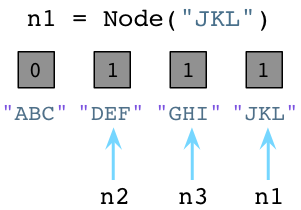
与之前一样,Python设置JKL的引用数为1。然而,请注意由于我们改变了n1指向了JKL,不再指向ABC,Python就把ABC的引用数置为0了。
此刻,Python垃圾回收器立刻挺身而出!每当对象的引用数减为0,Python立即将其释放,把内存还给操作系统: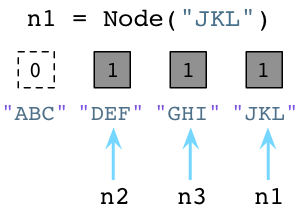
上面Python回收了ABC Node实例使用的内存。Python的这种垃圾回收算法被称为引用计数。是George-Collins在1960年发明的。你可以想象,有个患有轻度OCD(一种强迫症)的室友一刻不停地跟在你身后打扫,你一放下脏碟子或杯子,有个家伙已经准备好把它放进洗碗机了!
现在来看第二例子。加入我们让n2引用n1:
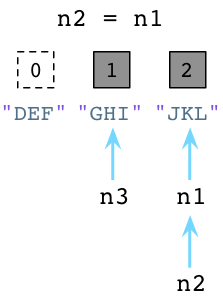
上图中左边的DEF的引用数已经被Python减少了,垃圾回收器会立即回收DEF实例。同时JKL的引用数已经变为了2 ,因为n1和n2都指向它。
1.2 循环引用
针对引用计数这种算法来说,如果一个数据结构引用了它自身,即如果这个数据结构是一个循环数据结构,那么某些引用计数值是肯定无法变成零的。为了更好地理解这个问题,让我们举个例子。下面的代码展示了前面我们所用到的节点类:

我们有一个构造器(在Python中叫做 init ),在一个实例变量中存储一个单独的属性。在类定义之后我们创建两个节点,ABC以及DEF,在图中为左边的矩形框。两个节点的引用计数都被初始化为1,因为各有两个引用指向各个节点(n1和n2)。
现在,让我们在节点中定义两个附加的属性,next以及prev
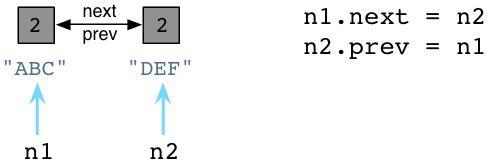
我们设置 n1.next 指向 n2,同时设置 n2.prev 指回 n1。现在,我们的两个节点使用循环引用的方式构成了一个双端链表。同时请注意到 ABC 以及 DEF 的引用计数值已经增加到了2。这里有两个指针指向了每个节点:首先是 n1 以及 n2,其次就是 next 以及 prev。
现在,假定我们的程序不再使用这两个节点了,我们将 n1 和 n2 都设置为null(Python中是None)。

好了,Python会像往常一样将每个节点的引用计数减少到1。但是这两个对象谁都没有外部引用。换句话说,我们的程序不再使用这些节点对象了,所以我们希望Python的垃圾回收机制能够足够智能去释放这些对象并回收它们占用的内存空间。但是这不可能,因为所有的引用计数都是1而不是0。Python的引用计数算法不能够处理互相指向自己的对象。
2. 标记-清除
标记-清除只关注那些可能会产生循环引用的对象,显然,像是PyIntObject、PyStringObject这些不可变对象是不可能产生循环引用的,因为它们内部不可能持有其它对象的引用。Python中的循环引用总是发生在container对象之间,也就是能够在内部持有其它对象的对象,比如list、dict、class等等。这也使得该方法带来的开销取决于container对象的的数量。另外,标记-清除只会关注新创建的对象,以及因为引用计数为零而被释放掉的对象的追踪
Python会循环遍关注列表上的每个对象,检查列表中每个互相引用的对象,根据规则减掉其引用计数的副本,然后根据reachable和unreachable规则进行垃圾回收。实际上这个规则是有点复杂的:
本质上:把这些container对象组成一个大集合,检测这个集合里的container对象有没有被其他container对象引用,如果有,那么直接计数-1.那么问题来了,加入A引用了B,B却没有引用A。按照我们制定的规则,B的ob_refcnt会变成0,然后被删除,但是实际上A和B并没有循环引用。所以如果直接按照这种逻辑处理,就会出现错误:A对B的引用变成了悬空引用。
所以Python这里加入了一个巧妙的设计:
step1:将对象的ob_refcnt复制,这样就有了ob_refcnt的副本。这样可以上述例子中的B的ob_refcnt变成0,从而避免悬空引用的出现。
step2: 根据副本ob_refcnt的值是否为0,将对象集合分为两个子集合:reachable和unreachable。reachable集合中的对象的副本ob_refcnt不为0,unreachable集合中的副本ob_refcnt为0,那么unreachable就是可以被回收的对象。回到例子中,A属于reachable,B属于unreachable。
step3: 检查reachable集合中的对象,如果其中有对象引用了unreachable集合中的对象,那么把unreachable集合中的这个对象放到reachable集合中来。回到例子中,因为A引用了B,所以B被从unreachable中调整到了reachable中。
step4: 检查step3中是否有新的对象从unreachable中调整到了reachable中;如果有,重复step3(考虑一下A引用B,B引用C的例子,你就知道step4的意义了)
step5: 清除unreachable集合中的对象。
缺点:标记和清除的过程效率不高。
显然,标记-清除是非常消耗系统资源的,所以下面又引入了分代收集的方法。
3. 分代收集
这种算法的根源来自于弱代假说(weak generational hypothesis)。这个假说由两个观点构成:首先是年亲的对象通常死得也快,而老对象则很有可能存活更长的时间。
换种说法:老对象因为已经存活很长时间了,是垃圾对象的可能性更小,所以检测频率可以降低。新对象是垃圾对象的概率大,所以检测频率要高一点才行。
分代收集的思想是:将系统中的所有内存块根据其存活时间划分为不同的集合,每个集合就成为一个“代”,垃圾收集频率随着“代”的存活时间的增大而减小,存活时间通常利用经过几次垃圾回收来度量。
Python默认定义了三代对象集合,索引数越大,对象存活时间越长。
Python的收集机制后,触发上边所说到的零代算法,释放“浮动的垃圾”,并且将剩下的对象移动到一代列表。
随着时间的推移,程序所使用的对象逐渐从零代列表移动到一代列表。而Python对于一代列表中对象的处理遵循同样的方法,一旦被分配计数值与被释放计数值累计到达一定阈值,Python会将剩下的活跃对象移动到二代列表。
通过这种方法,你的代码所长期使用的对象,那些你的代码持续访问的活跃对象,会从零代链表转移到一代再转移到二代。通过不同的阈值设置,Python可以在不同的时间间隔处理这些对象。Python处理零代最为频繁,其次是一代然后才是二代。
参考文献:
深入分析 Python 的垃圾回收机制 http://python.jobbole.com/82061/